Experiment 000: One-Layer Global Throttle Sanity Check
Status: Valid
Notebook: workspace/ablations/000_global_throttle_sanity/notebooks/affine_drift_controler_no_quant.ipynb
Purpose
This is the first working sanity check for the dynamic global throttle idea.
The goal is not yet to test quantization, fixed-point rails, multiple layers, or the full ENABOL hardware path. The goal is narrower:
Can we build a custom Keras training loop that detects unstable online learning dynamics and globally throttles the learning update so training does not diverge?
This test validates the instrumentation and controller on the simplest possible model.
Dataset
We start with a linear teacher with no bias first:
Then the output is generated by a linear teacher:
We use this exact teacher matrix:
Such that
The following image shows scatter plots of the input and target distributions, as well as their histograms at the bottom.
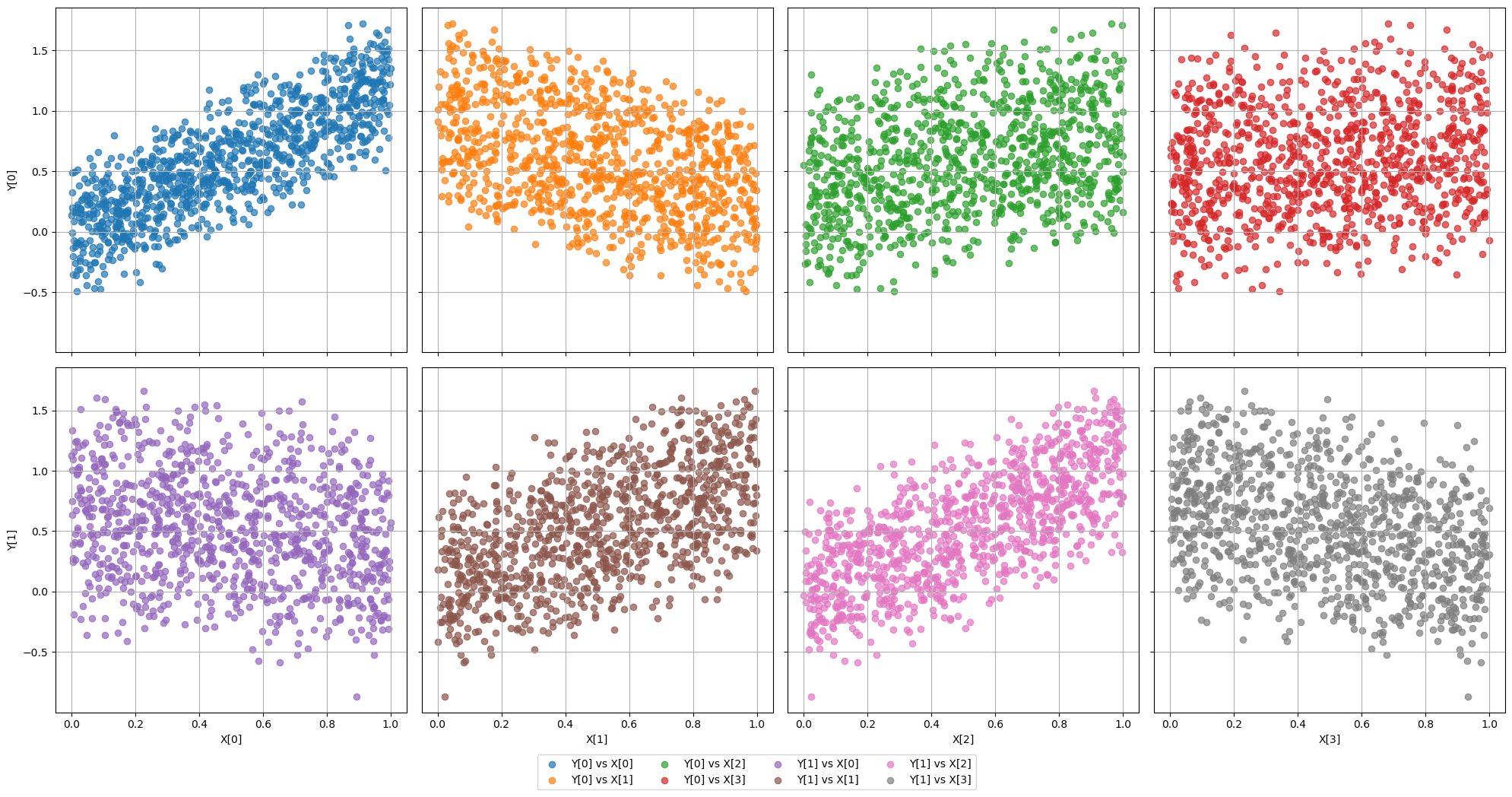
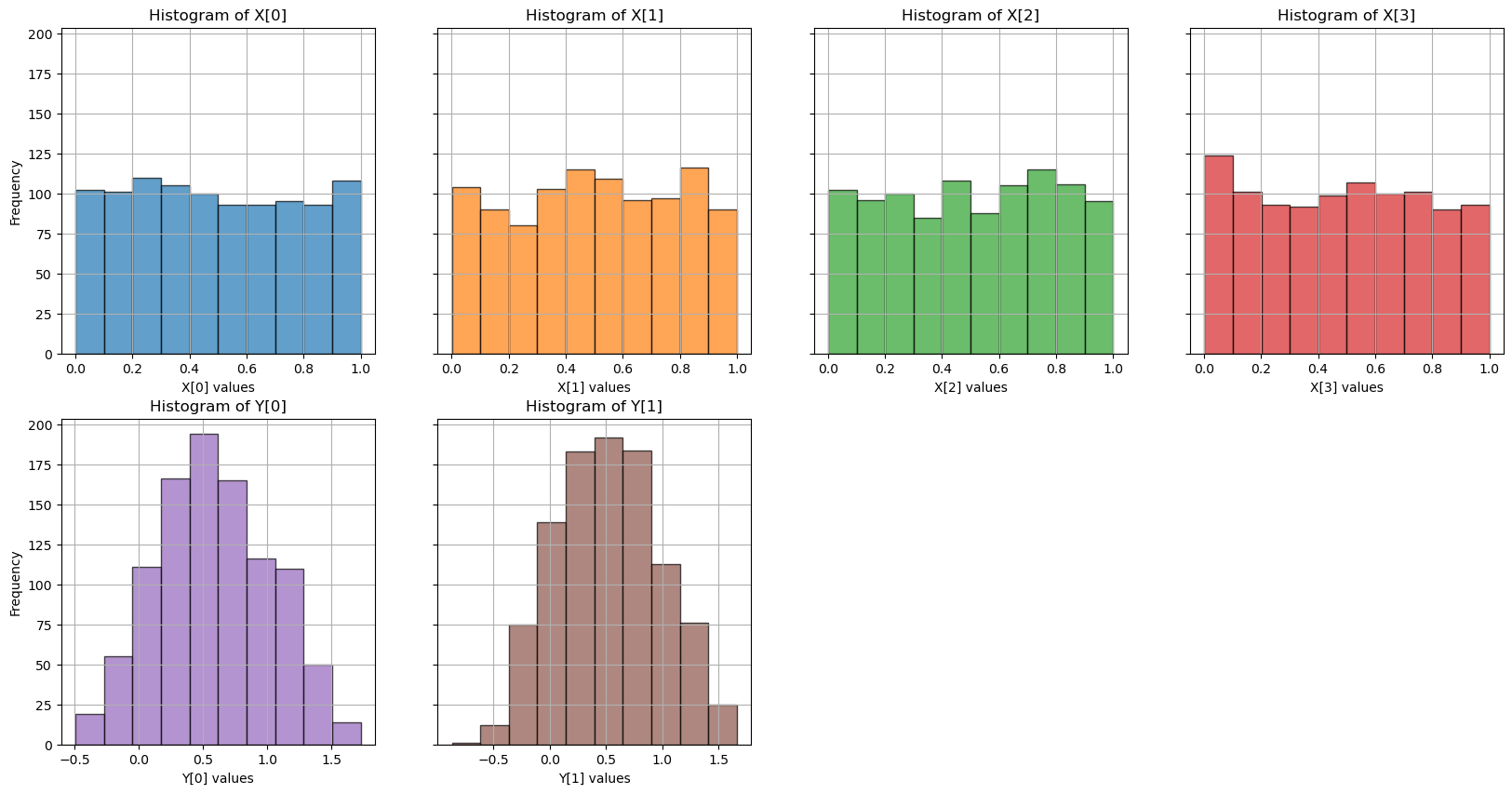
Code to generate the dataset:
If you need to understand the structure of this dataset, check here.
import kappa
# Create the dataset
dataset = kappa.AffineDataset(num_samples=1000, use_bias=False)
# Plot it
dataset.plot()
dataset.plot_histogram()
print(dataset)
# Get the data
X, Y = dataset.get()
which renders:
AffineDataset(
[Input] X:
Shape: (1000, 4)
Dtype: DataType.D2_FLOAT
X <- Uniform(-1, 1)
[Output] Y:
Shape: (1000, 2)
Dtype: DataType.D2_FLOAT
Y <- X @ A.T + b
---------
A = [[ 1.25 -0.75 0.5 0.2 ]
[-0.4 0.9 1.1 -0.6 ]]
b = [0. 0.]
----------
Analytic Hessian:
Lambda max: 1.0841
Eta max: 1.8448
)
Note that the dataset object is also giving the analytical hessian metrics. This is important because it means that:
Drift Model
Now let's assume a learning rate of . With no drift, the nominal margin is:
However, with a gain drift of , the Hessian grows approximately as:
which means the post-drift margin is:
When drifting the input gain by a factor of 4, the previously stable learning rate of becomes unstable. This is the regime where we expect the global throttle controller to intervene and prevent divergence.
Controller Behavior
Given the instability introduced by the drift, what we basically expect is that the controller should choose a throttle such that the effective learning rate is back in the stable region. In other words, we expect:
With the ideal post-drift throttle:
Then:
The global throttle reduces the optimal learning rate such that it stays in the stable region even after drift.
Model
The student model is a one-layer linear network without bias:
This keeps the Hessian and closed-loop stability story simple.
Code to build the model:
model = kappa.LinearBlockModel(dataset=dataset, num_hidden=[dataset.A.shape[0]],
activation=None, use_batchnorm=False, verbose=True,
use_bias=False, seed=0)
model.summary()
which returns
[INFO] - Building model with input shape (4,) and output shape (2,)
[INFO] - Added Dense layer with 2 units
Model: "LinearBlockModel"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓
┃ Layer (type) ┃ Output Shape ┃ Param # ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩
│ input_layer (InputLayer) │ (None, 4) │ 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ dense (Dense) │ (None, 2) │ 8 │
└─────────────────────────────────┴────────────────────────┴───────────────┘
Total params: 8 (32.00 B)
Trainable params: 8 (32.00 B)
Non-trainable params: 0 (0.00 B)
Current Notebook Flow
The notebook currently does three things:
- Builds a controlled affine dataset.
- Trains the one-layer model normally to confirm the task is learnable.
- Reinitializes the model, performs a nominal warmup, then enters a drifted online phase:
The notebook compares:
| Run | Controller | Purpose |
|---|---|---|
| Nominal baseline | off | Confirm the one-layer model learns the teacher. |
| Drift baseline | off | Show unstable behavior after gain drift. |
| Drift controlled | on | Show the global throttle can prevent divergence. |
What Is Being Tested
The custom trainer logs the quantities needed for closed-loop analysis:
- loss,
- RMSE,
- weight error,
- parameter norm,
- gradient norm,
- raw update norm,
- actual update norm,
- curvature proxy,
- curvature EMA,
- controller value
alpha(t), - effective learning rate,
- Hessian eigenvalue estimates,
- stability margins,
- update-map spectral radius,
- finite/divergence flags.
The controller globally scales the SGD update:
where:
The important property is that this scaling should preserve the update direction while reducing the effective learning rate.
Experiment 000A: Sanity check without drift nor quantization
Here we just make sure that our dataset and our model classes/objects are working as expected so we simply train them with a sane value for the learning rate, and without any drift. The code for this experiment:
h = model.train_instrumented(
X,
Y,
epochs=100,
batch_size=32, #dataset.num_samples, # Full-batch for clean Hessian metrics
learning_rate=0.05,
loss_mode="half_mse",
curvature_ema_rho=0.05,
chi=1.5,
use_controller=False,
compute_analytic_hessian=True,
reference_A=dataset.reference_weight_matrix,
)
print(h)
h.plot_results(title="Training History")
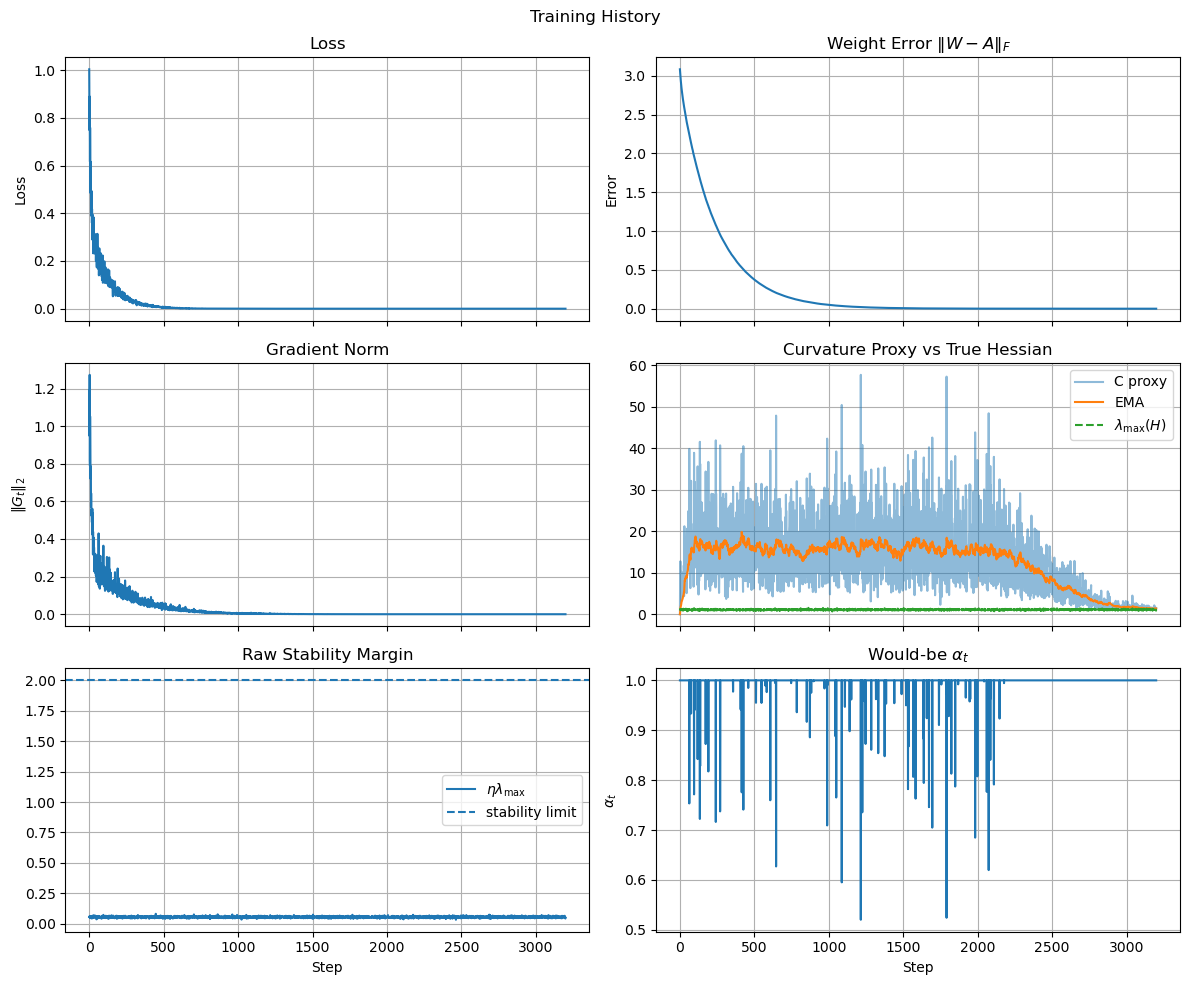
The result is shown in the image below, which confirms that the loss curve is smooth and converges to zero, as expected, without any instability or divergence.
Experiment 000B: Sanity check with drift but no controller
Here we introduce a gain drift in the input:
so that the task remains consistent while the Hessian grows approximately as:
Stage 0: Normal training without drift
First, we reintialize the model and run a nominal warmup phase to confirm that training starts in a stable regime. The code to generate this is:
# Reinit
model.reinitialize_weights()
# Phase 1: nominal warmup
h_nom = model.train_instrumented(
X,
Y,
epochs=20,
batch_size=len(X),
learning_rate=0.5,
use_controller=False,
reference_A=dataset.A,
)
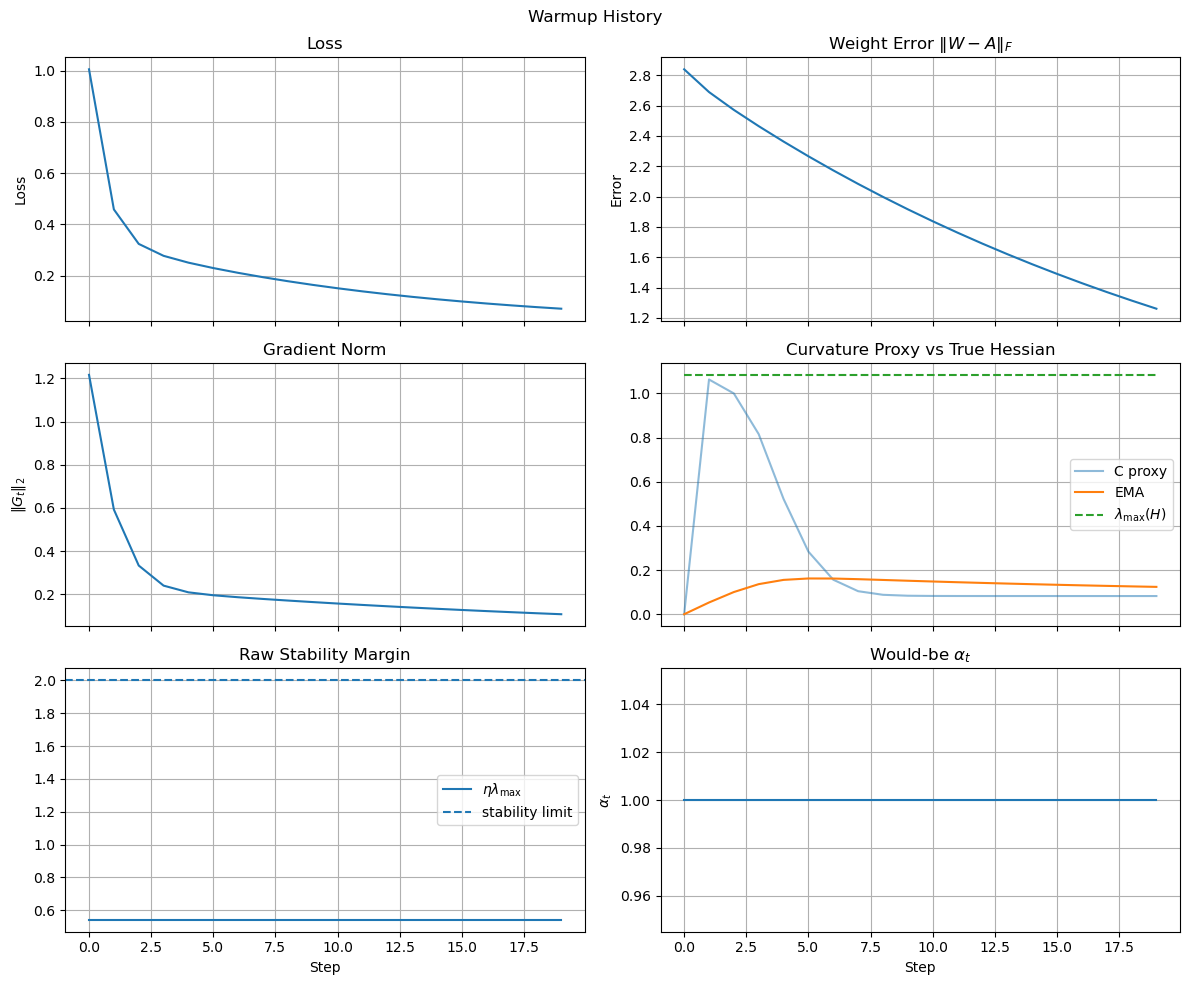
h_nom.plot_results(title="Warmup History")
The result is shown in the image below, which confirms that the model learns the task and converges to zero loss in a stable way.
Stage 1: drifted training without controller
Next, we introduce the gain drift and continue training without the controller to confirm that the training dynamics become unstable. The code to generate this is:
# Phase 2: sensor gain drift
gamma = 4.0
Xd = gamma * X
Yd = Y # important: target remains clean
h_drift = model.train_instrumented(
Xd,
Yd,
epochs=100,
batch_size=len(Xd),
learning_rate=0.5,
use_controller=False,
reference_A=dataset.A / gamma,
)
h_drift.plot_results(title="Drift History")
The result is shown in the image below, which confirms that the loss curve diverges after the drift is introduced, as expected.
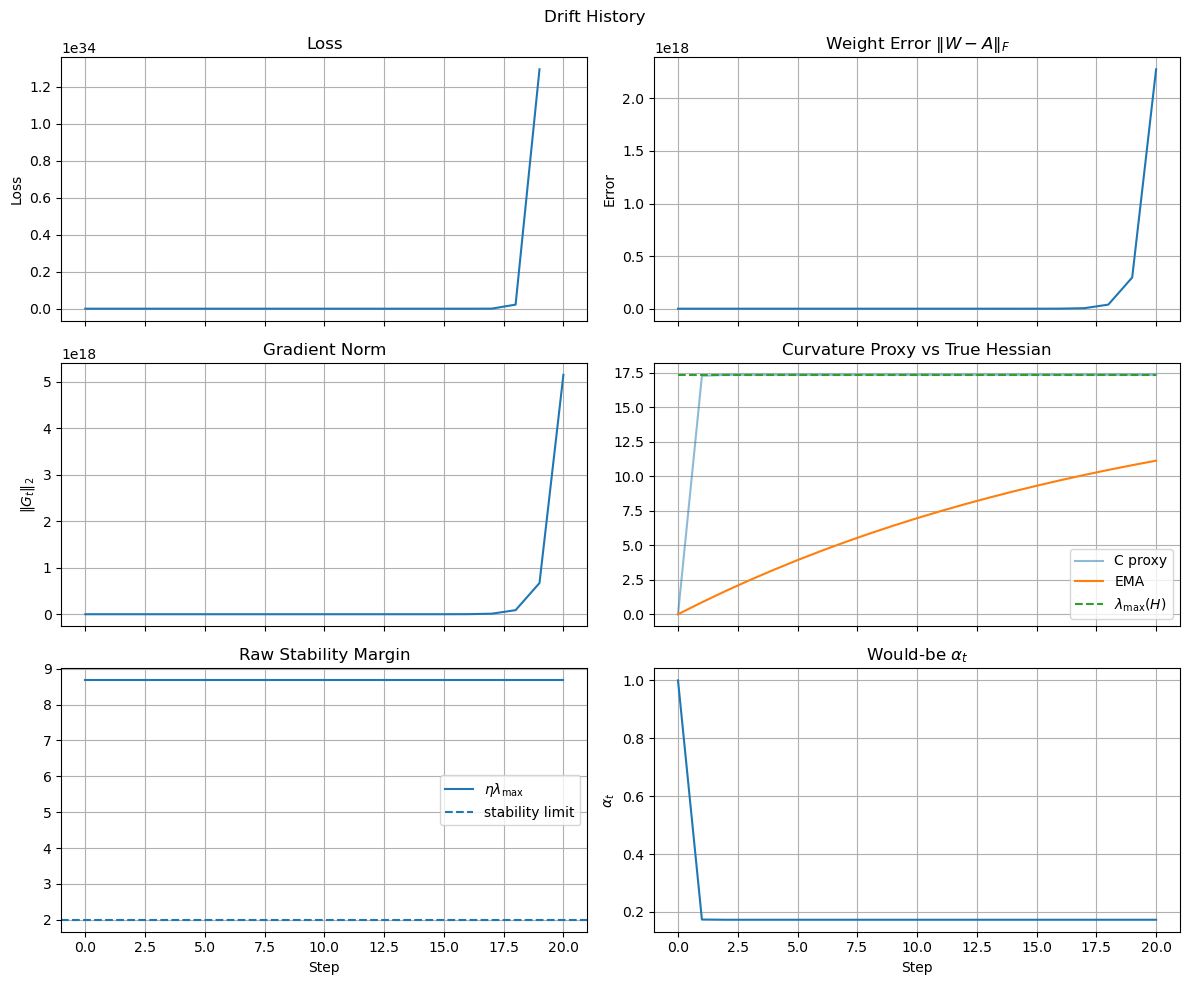
Experiment 000C: Sanity check with drift and controller
Finally, we run the same loop with the drifted data but now we turn on the controller to confirm that it can prevent divergence. The code to generate this is below (note that it's important that we reinitialize the model again to start from the same initial conditions as the previous runs, and that we use the same nominal warmup phase to give the controller a chance to estimate the curvature before the drift starts):
# Reinit
model.reinitialize_weights()
# Phase 1: nominal warmup
h_nom = model.train_instrumented(
X,
Y,
epochs=20,
batch_size=len(X),
learning_rate=0.5,
use_controller=False,
reference_A=dataset.A,
)
# Phase 2: sensor gain drift
h_drift = model.train_instrumented(
Xd,
Yd,
epochs=100,
batch_size=len(Xd),
learning_rate=0.5,
use_controller=True,
reference_A=dataset.A / gamma,
)
h_nom.plot_results(title="Warmup History")
h_drift.plot_results(title="Drift History")
The result is shown in the image below, which confirms that the loss curve remains stable and converges to zero even after the drift is introduced, thanks to the global throttle controller.
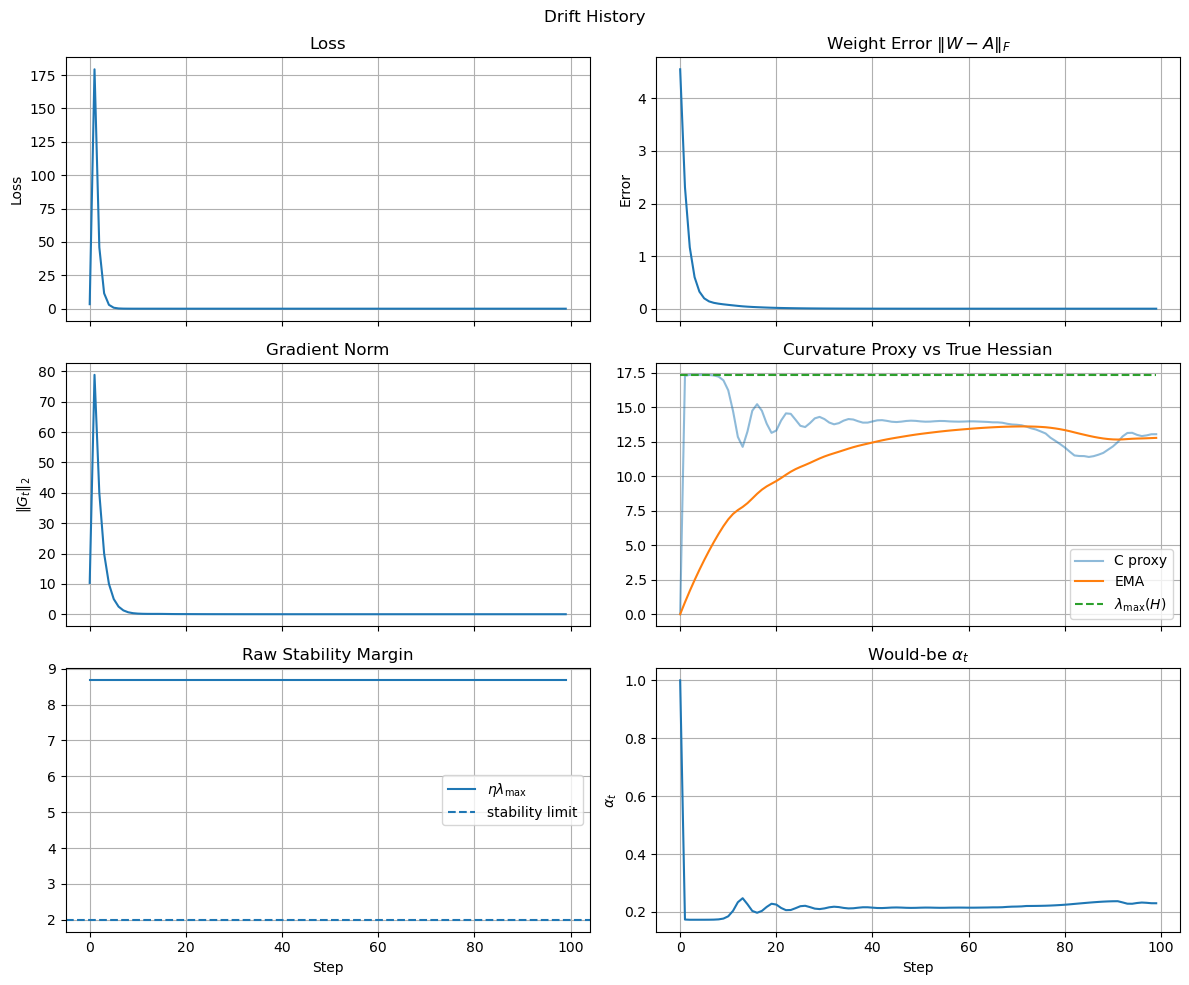
Summary of Results
Key Findings: This preliminary notebook supports the basic claim that a global controller can throttle the total learning rate and stabilize a one-layer online learning loop.
Notebook Preview
The notebook can be viewed directly on GitHub:
Open notebook on GitHubIf the iframe does not load, use the GitHub link above.